
Recherche
Warum langsames Denken bei der Recherche hilft
Von wegen objektiv: Journalistinnen und Journalisten nehmen die Welt aus ihrer eigenen Perspektive wahr – also eingeschränkt und oftmals verzerrt. Bei Algorithmen ist es ähnlich. Was aber hilft gegen den Bias?
von Christina Elmer
Zum Start ein Gedankenexperiment: Sie recherchieren für eine Reportage zur Entwicklung der Kriminalität in Ihrer Stadt. Wo spielt diese Reportage? Vermutlich haben Sie an einen bestimmten Stadtteil gedacht. Aber warum? Nachrichten, Statistik, eigene Erfahrungen – viele Faktoren können solche Assoziationen beeinflussen. In der Regel ist dieser Prozess aber unbewusst und lässt vieles außen vor, das wir eigentlich wissen oder wissen könnten. Zugleich: Bei der Masse an Informationen, die uns jeden Tag erreichen, sind derartige Filter und Schemata alternativlos. Kaffee oder Tee zum Frühstück? Schon damit wären wir sonst stundenlang beschäftigt.
Wir brauchen diese mentalen Abkürzungen, das ist die erste wichtige Erkenntnis. Sie sorgen dafür, dass wir uns überhaupt in der Welt bewegen können. Damit blenden wir aber viele Details und Perspektiven aus, die wir für ein ganzheitliches Verständnis unserer Umwelt bräuchten. Das ist die zweite Erkenntnis, die Kehrseite dieses Phänomens. Unsere Wahrnehmung ist eingeschränkt, mitunter empfindlich, häufig verzerrt.
Journalistinnen und Journalisten müssen sich dessen bewusst sein, wenn sie möglichst objektiv und vorurteilsfrei berichten wollen. Nur wer seine Filter kennt, kann sie hinterfragen und idealerweise öffnen. Wie das gelingen kann, wird dieser Beitrag an konkreten Beispielen zeigen.
Können uns Algorithmen dabei helfen? Viele halten technische Systeme für neutral und unparteiisch – da wäre es doch ideal, den in seiner Objektivität arg begrenzten Menschen durch Algorithmen zu ersetzen, die auf Basis großer Datenmengen die viel besseren Entscheidungen treffen! Doch so einfach ist es leider nicht, denn auch technische Systeme sind limitiert: Sie können nur den Teil der Realität erfassen, der sich in ihren Datenstrukturen abbilden lässt. Sie tragen oftmals strukturelle Verzerrungen in sich, wodurch sie Benutzergruppen diskriminieren können. Und bei lernenden Systemen ist entscheidend, dass sie mit sauberen, repräsentativen Daten gefüttert werden. Ansonsten passiert, was Informatiker „garbage in, garbage out“ nennen.
Überhaupt: Technische Systeme mögen leistungsfähiger sein als ihre Programmierer – aber wenn es darum geht, die Wirklichkeit objektiv abzubilden, sind sie mindestens ebenso eingeschränkt. Die Auswirkungen können dramatisch sein: Werden Algorithmen im großen Maßstab eingesetzt, vervielfältigen sich auch negative, diskriminierende Effekte. Manche Systeme geraten zudem in Rückkopplungsschleifen – etwa wenn sie in der Realität verzerrende Spuren hinterlassen, diese aber wiederum erfassen, um daraus zu lernen. Algorithmen sind daher längst zu einem Thema für investigative Recherchen geworden.
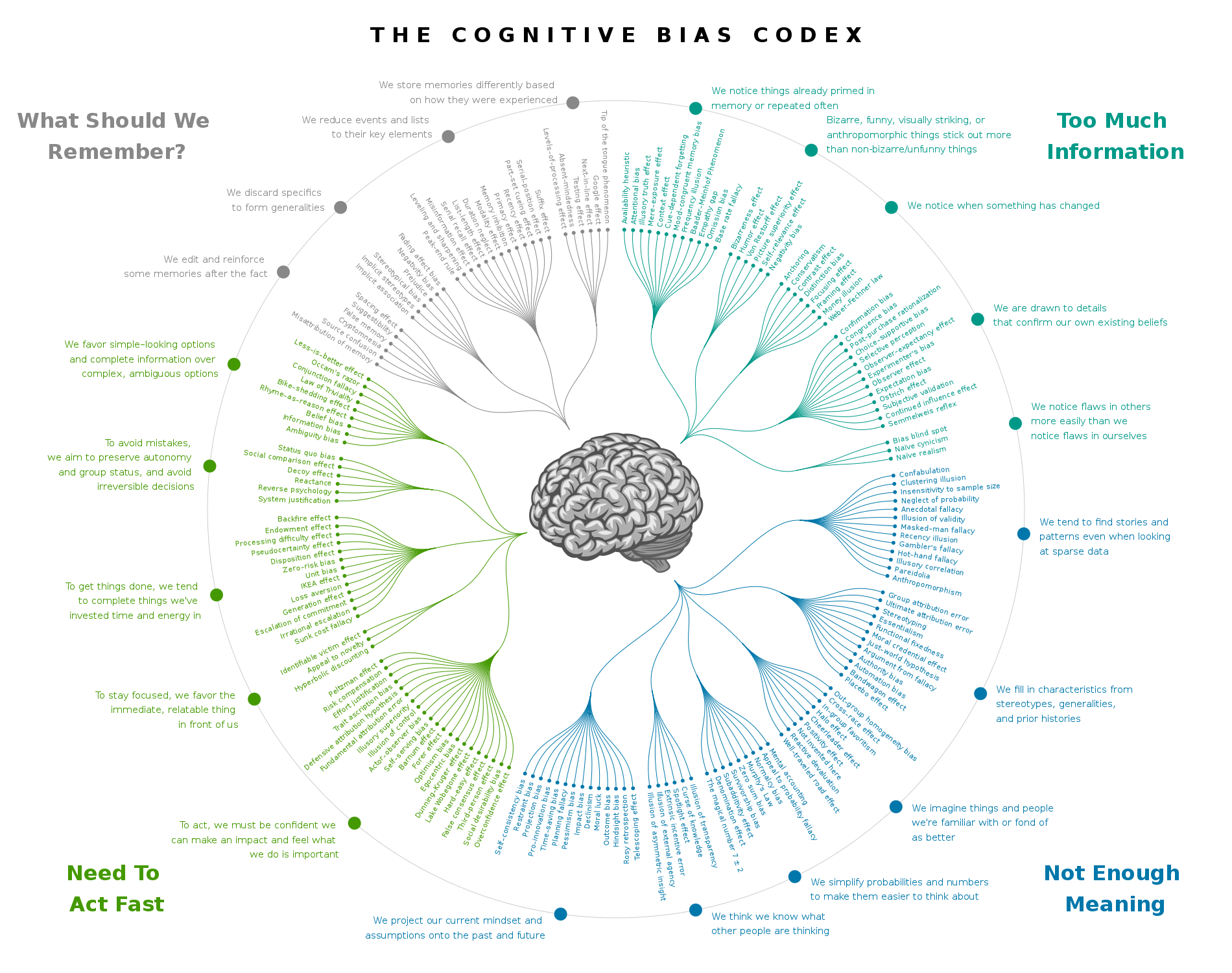
Übersicht zu kognitiven Verzerrungen / Quelle: The Cognitive Bias Codex – 180+ biases, designed by John Manoogian III (jm3) licensed with Cc-by-sa-4.0
Es lohnt sich also, derartige Effekte in beiden Systemen zu betrachten, dem technischen wie dem kognitiven. Wir lernen dabei, wie wir Algorithmen kritisch hinterfragen und vernünftiger aufsetzen können. Und wir machen uns bewusst, wo unsere eigenen Grenzen liegen – was uns wiederum ermöglicht, diese zu erweitern. Im Folgenden nehmen wir vier Phänomene in den Fokus: Wie wirken sie auf Menschen und in Algorithmen? Und was können Journalistinnen und Journalisten konkret tun?
-
Blinde Flecken
Geräusche, Gerüche und Geschmack, visuelle und taktile Reize – unsere Umwelt nehmen wir über die Sinne wahr. Das Gehirn erreichen dabei unzählige Informationen, die zunächst weder verknüpft noch vollständig sind. Und trotzdem gelingt es uns, aus ihnen ein stimmiges Gesamtbild zu konstruieren. Um begreiflich zu machen, was um uns herum passiert, überbrückt das Gehirn Leerstellen und vermutet kausal-sinnvolle Zusammenhänge, wo keine sind. Aus dem wenigen, was wir über die Welt wissen, schließen wir also auf den Rest.
Der Psychologe Daniel Kahneman prägte für dieses Phänomen die Bezeichnung „WYSIATI – What you see is all there is“. Aus dem, was uns an Informationen zur Verfügung steht, bauen wir die bestmögliche Geschichte – das funktioniert sogar umso besser, je weniger Details wir kennen, die das sinngebende Narrativ stören könnten. Auch wenn wir Personen einschätzen, schließen wir voreilig vom Bekannten aufs Unbekannte. Bei diesem Halo-Effekt spielen die unmittelbar erfassbaren physische Merkmale eine große Rolle, sodass attraktiven Menschen häufig vorschnell weitere positive Eigenschaften zugeschrieben werden.
In der Recherche kann das gefährlich werden. Wenn Journalistinnen und Journalisten ein Thema in kurzer Zeit erschließen müssen, sollten sie bereit sein, es auch in seiner Komplexität und Widersprüchlichkeit zu erfassen. Schließlich ergibt nicht alles Sinn, nicht jede Entwicklung folgt einem klaren Narrativ und nicht jeder telegene Interviewpartner muss auch die besten Zitate liefern. Das bewusst anzuerkennen, ist schon der erste wichtige Schritt im sogenannten Debiasing, mit dem wir aktiv gegen Verzerrungen vorgehen können.
Daneben hilft alles, was den eigenen Horizont erweitert. Der Austausch mit Kolleginnen und Kollegen in einer möglichst diversen Redaktion, nicht nur bezogen auf Alter und Geschlecht, sondern auch auf Bildungshintergrund und soziale Herkunft. Weitere Quellen zum Thema der Recherche einzuholen, die es aus einer ganz anderen Perspektive beurteilen. Ambiguitäten auszuhalten und sie letztlich auch innerhalb des journalistischen Beitrags zu kommunizieren. Besonders wirkungsvoll beim Erlernen von Debiasing-Methoden sind offenbar Training und direktes Feedback: Forscher der Boston University konnten zeigen, dass Probanden die Techniken mithilfe von Videospielen deutlich besser verinnerlichten, verglichen mit einem Erklärvideo über kognitive Verzerrungen.
Den Blick zu weiten und zu differenzieren – bei Algorithmen geht das kaum, dabei wäre es auch hier wahnsinnig hilfreich. Denn auch technische Systeme können qua Design nur auf bestimmte Informationen zugreifen. Was für sie nicht als Input definiert wurde oder ihnen nicht zugänglich gemacht wird, bleibt unberücksichtigt.
Wohin das führen kann, zeigt ein Experiment der Washington Post: Die Voice-Assistenten in Amazon Echo und Google Home verstanden dabei Menschen mit spanischem oder chinesischem Akzent messbar schlechter als solche mit akzentfreiem Englisch. Der Mechanismus dahinter: Die ersten Nutzer kamen tendenziell aus höheren gesellschaftlichen Schichten, waren besser gebildet und hatten seltener einen Migrationshintergrund. Und mit ihren Daten lernten die Systeme, mithilfe von künstlicher Intelligenz, und wurden immer besser – allerdings nur für genau diese Nutzergruppen. Anderen wurde hingegen der Zugang erschwert, ohne dass die Verantwortlichen das bewusst implementiert hätten. Sie hatten lediglich zugelassen, dass zur Optimierung ihrer Assistenten keine repräsentativen, sondern lückenhafte Daten genutzt wurden.
Am Ende waren auch die Systeme selbst verzerrt und behandelten ihre Nutzer ungleich – eine Schieflage in der Gesellschaft hatte sich auf die Algorithmen übertragen. Zudem kann so ein Rückkopplungseffekt entstehen: Wenn zunehmend weniger Menschen mit Migrationshintergrund die Geräte nutzen, weil sie sich schlechter verstanden fühlen, bekommen die Systeme immer weniger Daten aus dieser Gruppe. Und der Bias verstärkt sich weiter.
-
Durch Daten diskriminiert
Wer also gehofft hatte, Maschinen würden Menschen generell neutral und frei von Vorurteilen behandeln, wird schon mit diesem ersten Beispiel enttäuscht. Viele weitere zeigen: Algorithmen können aus vielen Gründen unfair entscheiden – weil sie bewusst oder unbewusst so programmiert wurden, dass sie später bestimmte Gruppen in der Bevölkerung ungleich behandeln. Oder weil sie mithilfe von Datensätzen lernen, die systematisch verzerrt sind. Häufig entstehen diskriminierende Effekte durch Korrelationen. Dabei tritt eine für den Algorithmus relevante Eigenschaft einer Person mit weiteren Merkmalen gehäuft auf, die dadurch einen ähnlichen Einfluss auf das Ergebnis bekommen.
Eine solche Eigenschaft ist die Anzahl der Umzüge, die Menschen in ihrem Leben bislang erlebt haben – jedenfalls, wenn es um die Einschätzung ihrer Kreditwürdigkeit geht. Unsere Recherchen zum Schufa-Algorithmus mit den Datenteams von BR und SPIEGEL zeigten, dass sich Umzüge negativ auf das Scoring-Ergebnis auswirken. Wie kann das sein? Offenbar korrelieren Umzüge mit weiteren Faktoren, die dafür sorgen, dass jemand einen Kredit nicht bedienen kann – genauso wie Alter und Geschlecht. Männer unter 25 Jahren haben demnach ebenfalls tendenziell ein höheres Risiko. Im Ergebnis hat also ein junger Mann, der aus völlig profanen Gründen überdurchschnittlich häufig umgezogen ist, direkt eine geringere Chance auf ein gutes Schufa-Scoring.
In anderen Bereichen sind Frauen die Leidtragenden. In ihrem Buch „Invisible Women“ beleuchtet Caroline Criado Perez die Mechanismen, die zur Benachteiligung von Frauen in unterschiedlichen Lebensbereichen führen. Nicht selten deshalb, weil man sich mit ihren spezifischen Bedürfnissen nicht ausreichend beschäftigte – mit teils lebensgefährlichen Folgen. So waren Frauen in der kardiologischen Forschung zu Herzinfarkten lange unterrepräsentiert, obwohl ihre Symptome sich von denen männlicher Betroffener unterscheiden. Das Yentl-Syndrom beschreibt die möglichen Folgen – zu spät gestellte Diagnosen, höhere Mortalitätsraten.
Solche Effekte können verstärken, was in der Gesellschaft ohnehin zu häufig vorkommt – Menschen diskriminieren einander, weil sie oftmals unreflektiert ihren Vorurteilen und Assoziationen folgen. Das hängt auch mit unserer Wahrnehmung zusammen: Was besser zu unseren Einstellungen passt, das nehmen wir intensiver wahr – und durch diesen Confirmation Bias werden sie zusätzlich bestätigt. Das Weltbild wird somit stabilisiert, wenn nicht zementiert. Wie wichtig diese Stabilität für das Gehirn offenbar ist, zeigt auch die Vielzahl an weiteren psychologischen Phänomenen, die dafür sorgen, dass wir uns bloß nicht zu viel mit den Ambiguitäten unserer komplexen Umwelt beschäftigen müssen.
Dabei wäre das in der Recherche häufig wertvoll. Hier können Journalistinnen und Journalisten eine Debiasing-Methode aus der Medizin anwenden, das Cognitive Forcing. Es soll uns helfen, gerade in zeitkritischen Situationen aus dem schnellen in einen langsameren Denkmodus zu kommen – und somit auch die eigenen Gedanken reflektieren zu können. Dafür werden zum Beispiel Checklisten genutzt, mit denen eigene Entscheidungen systematisch hinterfragt werden: Bist Du Dir sicher – und warum? Passen die Daten zusammen, fehlt etwas? Was, wenn das Gegenteil stimmt?
Auch als Journalistinnen und Journalisten können wir uns gezielt mit solchen Anreizen zur Reflexion konfrontieren. Oder wir institutionalisieren den Zweifel, etwa mithilfe von Rollenspielen, bei denen eine Person als Fundamentalkritiker auftritt und die Ergebnisse einer Recherche schonungslos hinterfragt. Ein solcher Advocatus Diaboli soll dem Team ermöglichen, auch kontroverse Positionen zu diskutieren, eigene Argumente zu schärfen und Ideen zu überprüfen. Wer diese Rolle innehat, kann jeden noch so absurden Punkt anbringen, ohne dass das Teamgefüge darunter leidet.
Auch Gedankenexperimente wie die Premortem-Methode können Fehlschlüsse offenbaren. Dabei versetzt sich ein Team in die fiktive Lage des Scheiterns und ermittelt die Ursachen: Was könnte dafür gesorgt haben, dass wir nicht weiter gekommen sind? Was haben wir übersehen, wo waren wir zu schnell? Diese Punkte gilt es im weiteren Verlauf aus dem Weg zu räumen – oder zu umschiffen.
Kritisches Denken braucht also einen festen Platz in der Recherche. Gefördert wird es auch dadurch, dass wissenschaftliche Methoden und Experimente regelmäßig eingesetzt werden. Dabei sind diverse Formate denkbar: eigene Nutzerstudien und Befragungen, das A/B-Testing möglicher Alternativen oder die Auswertung statistischer Datenquellen in der Recherche. Wer immer wieder aussagekräftige Daten über sein Thema hinzuzieht, kann damit andere Ergebnisse abgleichen und die eigenen Schlüsse hinterfragen. Algorithmen können schließlich dabei helfen, größere Datenmengen zugänglich zu machen.
-
Dimensional eingeschränkt
Überhaupt, die eigenen Grenzen. Alle denkbaren Quellen in eine Recherche einbeziehen zu können, ist natürlich illusorisch – unsere Perspektive bleibt also eingeschränkt. Zwar können wir sie erweitern, indem wir gezielt nach den Lücken in unseren Quellen fragen und diese ausleuchten. Aber im Ergebnis können wir die Komplexität unserer Umwelt natürlich nicht adäquat abbilden, auch wenn wir unbegrenzt Zeit und Ressourcen hätten. Wir können höchstens versuchen, ihr gerecht zu werden – auch indem wir die Grenzen der Recherche unserem Publikum gegenüber transparent machen.
Auch Algorithmen sind grundsätzlich limitiert, in mehrfacher Hinsicht. Schon durch ihr Design sind sie auf bestimmte Funktionalitäten und Datenquellen festgelegt. Sie können ohnehin nur solche Informationen verarbeiten, die sich in Daten ausdrücken lassen. Und natürlich benötigen algorithmische Systeme letztlich Strom, Speicherplatz und Rechenkapazität. Wenn wir Algorithmen nutzen, um Phänomene aus unserer Umwelt zu beschreiben, muss uns das bewusst sein – ebenso wie die qualitativen, kontinuierlichen und widersprüchlichen Dimensionen, die mit ihnen nicht abgebildet werden können.
Nicht selten heißen diese Dimension Fairness oder Humanität. Als sich im Herbst 2017 Hurrikan Irma auf Florida zubewegte, entschieden sich viele Einwohner in kurzer Zeit dazu, die Region zu verlassen. Entsprechend viele Menschen suchten auf den Webseiten der großen Fluggesellschaften nach Tickets – und waren entsetzt über die Preise, die teils auf das Zehnfache des Üblichen gestiegen waren. Mehrere tausend Dollar sollte ein Flug nach New York kosten. Dafür hatten Algorithmen gesorgt, mit denen die Fluggesellschaften die Ticketpreise an herkömmlichen Tagen an die Nachfrage anpassen. Immerhin: Die Airlines reagierten und begrenzten die Preise wieder.
Das Beispiel Irma zeigt eindrucksvoll, was passieren kann, wenn wir sensible Entscheidungen an Algorithmen auslagern, gerade in kritischen Situationen. Auf Notsituationen kann kein technisches System von sich aus adäquat reagieren. Es bräuchte dafür ein konkretes Verfahren und entsprechende Daten. Vor allem aber müsste im Vorfeld geklärt werden, welche Werte bei der Reaktion des Algorithmus im Vordergrund stehen sollen und was diese konkret bedeuten sollen. Denn allein für Fairness gibt es diverse mögliche Definitionen.
Demonstrieren lässt sich das am Beispiel des COMPAS-Algorithmus. Er wird an US-Gerichten genutzt, um zu prognostizieren, ob ein angeklagter Straftäter rückfällig wird. In einer aufwendigen Recherche konnte ein Team des US-Newsrooms ProPublica belegen, dass der Algorithmus farbige Personen systemisch diskriminierte. Deutlich häufiger als weißen wurde ihnen fälschlicherweise ein zu hohes Risiko unterstellt. Falsch positive Befunde waren in dieser Gruppe also überrepräsentiert. Forscher konnten daraufhin zeigen, dass sich dieser Effekt nicht vermeiden lässt, wenn die tatsächlichen Rückfallquoten der beiden Gruppen weit auseinanderliegen – so wie es hier der Fall ist.
Zudem ist auch nicht eindeutig, was Fairness in diesem Zusammenhang bedeutet. Sollen die falsch positiven oder die falsch negativen Befunde gleichverteilt sein? Oder soll die Vorhersagekraft auf beiden Seiten gleich präzise sein? Das sind alles denkbare Wege, die Zielsetzung der Fairness zu operationalisieren – neben vielen weiteren. Welcher im konkreten Fall sinnhaft ist, hängt natürlich vom Thema und den jeweiligen Nebenwirkungen ab. Und davon, welche Werte im Vordergrund stehen sollen.
-
Zielgruppe verfehlt
Auch wenn bei der Entwicklung eines Algorithmus alle Vorkehrungen gegen Verzerrungen getroffen wurden – richtig spannend wird es ohnehin erst, wenn er sich in der Realität beweisen muss. Denn die ist nicht nur komplex, sondern in vieler Hinsicht unvorhersehbar. Die Gesellschaft entwickelt sich weiter und gewinnt neue Erkenntnisse, ebenso kann sich die Dateninfrastruktur ändern. Nicht selten werden Algorithmen zudem in Kontexten eingesetzt, für die sie nicht entwickelt wurden – ob bewusst oder unbewusst – oder weil sich die Umwelt schlicht verändert hat.
Aktuell zeigt sich das eindrucksvoll bei der Gesichtserkennung auf Smartphones. In einigen Landesteilen Chinas sind Atemmasken obligatorisch, um eine Ausbreitung des Coronavirus zu verhindern. Wer sie trägt, kann aber sein Smartphone nicht mehr via Gesichtserkennung entsperren und benötigt mehr Zeit, um damit zu bezahlen. Kein Wunder, dass bereits Prototypen für Atemmasken entwickelt wurden, auf die das eigene Gesicht gedruckt ist – als perfektes Imitat, sichtbar optimiert für die Gesichtserkennung, eher nicht für das Sozialleben.
Wie Algorithmen müssen auch Medien zum Nutzungskontext passen – mehr noch, zu ihren Nutzerinnen und Nutzern. Seinen gesellschaftlichen Auftrag kann schließlich nur erfüllen, wer Menschen erreicht, wer ihre Lebenswirklichkeiten und Bedürfnisse ernst nimmt. Aus dem Newsroom heraus ist es mitunter schwierig, diese Perspektiven mitzudenken – oftmals haben Journalistinnen und Journalisten kaum persönlichen Kontakt zu ihren Zielgruppen und können sich zu selten mit konkretem Feedback zu ihrer Arbeit beschäftigen.
Dabei gäbe es viele Formate, um den Austausch zwischen Redaktion und Rezipienten zu verstärken. Persönliche Treffen und Nutzerbefragungen, Gruppen in sozialen Netzwerken und Konferenzen – um nur einige zu nennen. Die Persona-Methode kann ebenfalls dabei helfen, einen empathischen Zugang zu eigenen Zielgruppe zu entwickeln. Dabei werden fiktive Personen entwickelt, die exemplarisch für zentrale Eigenschaften und Bedürfnisse wichtiger Nutzergruppen stehen. Je konkreter Personas beschrieben sind, desto wirkungsvoller können sie eingesetzt werden – in der Entwicklung neuer Produkte und Formate, aber ebenso im Redaktionsalltag.
Wer auf diese Weise ein gutes Gespür für seine Rezipienten entwickelt hat, der kann aus dem Bauch heraus abschätzen, ob sie den eigenen Beitrag relevant oder nützlich finden würden, ob er sie im richtigen Moment und im passenden Format erreicht. Genau um dieses gut informierte Bauchgefühl geht es. Muss es schnell gehen, etwa in nachrichtlichen Großlagen, dann steuert es die unmittelbaren Entscheidungen. Auch wenn es uns einmal nicht gelingt, in den langsamen Denkmodus zu wechseln.
Christina Elmer ist Geschäftsführende Redakteurin im Bereich Redaktionelle Entwicklung und stellvertretende Entwicklungschefin des SPIEGEL.
Referenzen und weiterführende Literatur
- Courtland, R.: Bias detectives: the researchers striving to make algorithms fair. Nature News Feature, 2018. Beitrag unter: https://www.nature.com/articles/d41586-018-05469-3
- Criado-Perez, : Invisible Women: Data Bias in a World Designed for Men. New York, 2019.
- Croskerry, P.: „The Cognitive Imperative: Thinking about How We Think.” Academic Emergency Medicine 7 (11), 2000, S. 1223–31. Beitrag unter https://onlinelibrary.wiley.com/doi/pdf/10.1111/j.1553-2712.2000.tb00467.x
- Diakopoulos, N.: The Algorithms Beat & Elmer, C: Algorithms in the Spotlight: Collaborative Investigations at Spiegel Online, in: Bornegru, L. / Gray, J.: Data Journalism Handbook (new edition), Kapitel 6/7, 2018. Beiträge unter https://datajournalism.com/read/handbook/two
- Friedman, B./Nissenbaum, H.: Bias in Computer Systems, in: ACM Transactions on Information Systems, Vol. 14, Nr. 3, 1996, S. 330-347. Beitrag unter https://nissenbaum.tech.cornell.edu/papers/biasincomputers.pdf
- Kleinberg, J./Mullainathan, S./Raghavan, M.: Inherent Trade-Offs in the Fair Determination of Risk Scores, in: 8th Innovations in Theoretical Computer Science Conference, 2017. Beitrag unter: https://drops.dagstuhl.de/opus/volltexte/2017/8156/pdf/LIPIcs-ITCS-2017-43.pdf
- Zweig, Katharina: Ein Algorithmus hat kein Taktgefühl. Wo künstliche Intelligenz sich irrt, warum uns das betrifft und was wir dagegen tun können. München, 2019.